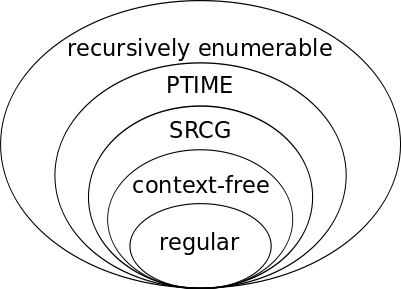
In Herrn Raus Blog gibt es eine schöne mehrteilige Einführung in formale Sprachen, formale Grammatiken und die Chomksy-Hierarchie. Unter anderem werden dort reguläre Grammatiken, kontextfreie Grammatiken und kontextsensitive Grammatiken vorgestellt. Ich will heute einen weniger bekannten Grammatikformalismus vorstellen: Simple Range Concatenation Grammars (SRCG) (zu deutsch etwa: einfache Intervallverkettungsgrammatiken).
SRCGs können alle kontextfreien Sprachen beschreiben und darüber hinaus einige, aber nicht alle kontextsensitiven Sprachen. Genaueres dazu sage ich in Teil 2 dieser Serie, bevor ich in Teil 3 andeute, wozu das speziell bei natürlichen Sprachen (also so etwas wie Englisch, Deutsch, Niederländisch oder Zürichdeutsch) und damit für die Computerlinguistik von Nutzen sein kann.
Fangen wir mit einer guten alten kontextfreien Grammatik an. Hier sind die Regeln einer kontextfreien Grammatik, die die Sprache {anbn|n≥0} erzeugt, also die Sprache, die aus den Wörtern ε (das leere Wort), ab, aabb, aaabbb usw. besteht.
(1.1) S → aSb
(1.2) S → ε
Wenn wir diese Grammatik als SRCG schreiben, sehen die Regeln so aus:
(2.1) S(aXb) → S(X)
(2.2) S(ε) → ε
Vergleichen wir Regeln (1.1) und (2.1): Beide Regeln besagen, dass man aus dem Symbol S alle Wörter ableiten kann, die mit a losgehen, in der Mitte aus etwas bestehen, das man wiederum aus S ableiten kann, und mit b enden. Die Beschreibung „dessen, was man ableiten kann“, steht bei SRCG nicht auf der rechten Seite des Pfeils, sondern in Klammern neben dem Symbol der linken Seite. Es wird die Variable X verwendet, die auf der rechten Seite in dem Ausdruck S(X) wieder auftaucht: Der sagt, dass X etwas sein muss, das man aus S ableiten kann.
Regel (2.2) besagt wie Regel (1.2), dass man aus S den leeren String ableiten kann, und zwar bedingungslos – es tauchen keine weiteren Symbole auf, deswegen ist auch die rechte Seite leer (geschrieben wie der leere String als ε).
Eine andere SRCG für dieselbe Sprache wäre die hier:
(3.1) S(XY) → A(X, Y)
(3.2) A(aX, bY) → A(X, Y)
(3.3) A(ε, ε) → ε
Hier taucht ein neues Nichtterminal auf, A. Was hinter A in Klammern steht, besteht aus zwei Teilen, man sagt: A ist zweistellig oder: A hat zwei Argumente. Eins für den a-Teil der Wörter und eins für den b-Teil.
Damit sind wir beim wesentlichen Unterschied zwischen SRCG und CFG: In CFGs kann man aus einem Nichtterminal einen Teilstring des Wortes ableiten, in SRCGs auch mehrere Teilstrings, technisch ausgedrückt: Tupel von Teilstrings.
Die Grammatik im Beispiel funktioniert so: Regel (3.3) sagt, dass aus A das Tupel ⟨ε, ε⟩ ableitbar ist, also zweimal der leere String. Regel (3.2) sagt: Wenn aus A das Tupel ⟨X, Y⟩ ableitbar ist (rechte Seite), dann ist aus A auch das Tupel ⟨aX, bY⟩ ableitbar (linke Seite). Generativ, prozedural und salopp ausgedrückt klatscht diese Regel vorne an das erste Argument von A ein a und an das zweite ein b. Diesen Prozess kann man beliebig oft wiederholen, bis man so viele a’s und b’s hat, wie man will – aber immer für beide Argumente gleichzeitig, sodass die Anzahl der a’s und b’s gleich bleibt. Schließlich kommt Regel (3.1) zum Zuge, die die beiden Argumente von A in das einzige Argument von S konkateniert (verkettet).
Man kann diesen Prozess auch in der umgekehrten Reihenfolge schreiben, als Ableitung. Eine Ableitung beginnt mit dem Startsymbol und dem Wort, das man ableiten will, und gelangt über die Anwendung von Regeln zu ε. Hier eine beispielhafte Ableitung für das Wort aabb:
S(aabb) ⇒(3.1) A(aa, bb) ⇒(3.2) A(a, b) ⇒(3.2) A(ε, ε) ⇒(3.3) ε
Weil jede Ableitung mit genau einem String beginnt (eben dem Wort, das man ableiten will), muss das Startsymbol immer einstellig sein. Die Stelligkeit ist für jedes Nichtterminal festgelegt, d.h. innerhalb einer Grammatik kann A z.B. nicht einmal mit zwei und einmal mit drei Argumenten auftauchen.
Während sich bei jeder Anwendung einer CFG-Regel an einer Stelle im abzuleitenden Wort etwas ändert – ein Nichtterminal wird durch etwas ersetzt – kann sich bei der Anwendung einer SRCG-Regel an mehreren Stellen etwas ändern. So ändert sich bei jeder Anwendung unserer Regel (3.2) sowohl vorne etwas (ein a wird hinzugefügt) als auch in der Mitte (ein b wird hinzugefügt). Leicht lässt sich das auf drei Stellen ausdehnen, sodass die Grammatik die Sprache {anbncn|n≥1} beschreibt, für die es schon keine CFG mehr gibt. Man gibt A einfach ein drittes Argument:
(4.1) S(XYZ) → A(X, Y, Z)
(4.2) A(aX, bY, cZ) → A(X, Y, Z)
(4.3) A(ε, ε, ε) → ε
Das ist jetzt eine so genannte 3-SRCG, d.h. eine SRCG, wo die Nichtterminale maximal 3 Argumente haben. Die Zeitkomplexität des Wortproblems (algorithmisch zu bestimmen, ob ein gegebenes Wort zu der von der Grammatik erzeugten Sprache gehört) nimmt für k-SRCGs mit steigendem k exponenziell zu (übrigens auch mit der maximalen Länge der rechten Regelseite, die bisher in allen Beispielen 0 oder 1 war). CFGs entsprechen 1-SRCGs, wie ganz oben illustriert, wo wir eine CFG direkt in eine 1-SRCG übersetzt haben.
Für die Form der Regeln einer SRCG gibt es zwei wichtige Einschränkungen: Auf der rechten Seite muss jedes Argument nicht mehr und nicht weniger als eine Variable enthalten (während auf der linken Seite Folgen von Terminalen, Variablen oder auch ganz leere Argumente erlaubt sind). Außerdem muss jede Variable, die in einer Regel vorkommt, auf der linken und auf der rechten Seite der Regel je genau einmal vorkommen. Ohne diese Einschränkungen hätte man die noch einmal deutlich mächtigeren und komplexeren Range Concatenation Grammars (RCG) (Boullier 1998).
In Teil 2 schauen wir uns etwas genauer an, welche Klassen von Sprachen SRCG und RCG beschreiben und wo man diese auf der Chomksy-Hierarchie einordnen kann.
Nachbemerkung 1: Aus pädagogischen Gründen habe ich immer „Regel“ und „Nichtterminal“ geschrieben, im RCG-Jargon sagt man eigentlich „Klausel“ und „Prädikat“ dazu. Wer schon einmal in Prolog programmiert hat, bei der klingt jetzt vielleicht ein Glöcklein. Ja, eine (S)RCG lässt sich mit trivialen Änderungen in der Syntax als Logikprogramm lesen. Leider ist das dann noch lange kein praxistauglicher Parser, wie ja auch Prologs im Kern kontextfreie Definite Clause Grammars (DCG) gewissen Beschränkungen unterworfen sind. Parsing-Algorithmen für RCG, SRCG und weitere Formalismen gibt’s in Kallmeyer (2010).
Nachbemerkung 2: Das war jetzt gewissermaßen auch eine Einführung in Linear Context-free Rewriting Systems (LCFRS) (Vijay-Shanker et al. 1987, Weir 1988) und Multiple Context-free Grammars (MCFG) (Seki et al. 1991). Diese beiden Grammatiktypen beschreiben dieselbe Klasse von Sprachen wie SRCG und unterscheiden sich auch sonst nur minimal davon.
Literatur
Pierre Boullier: A Generalization of Mildly Context-Sensitive Formalisms. In: Proceedings of the Fourth International Workshop on Tree-Adjoining Grammars and Related Formalisms (TAG+4), University of Pennsylvania, 1998.
Laura Kallmeyer: Parsing beyond Context-Free Grammars. Springer, 2010.
Hiroyuki Seki, Ryuichi Nakanishi, Yuichi Kaji, Sachiko Ando und Tadao Kasami: On Multiple Context-Free Grammars. In: Theoretical Computer Science 88(2), 1991.
K. Vijay-Shanker, David J. Weir und Aravind K. Joshi: Characterizing Structural Descriptions Produced by Various Grammar Formalisms. In: Proceedings of ACL, Stanford, 1987.
David J. Weir: Characterizing Mildly Context-Sensitive Grammar Formalisms. Dissertation, University of Pennsylvania, 1988.